Finding Value in Incremental Statistics, Pt. 2
Previously, I did a little investigation into incremental statistics and what benefit they can provide. The goal was to find the intersection of update timings for incremental and non-incremental statistics, with the hope of being able to demonstrate a reclamation of statistics maintenance times - and perhaps higher sample rates. Summary: we can, and auto_stats is a beneficiary. However, is this a solution in search of a problem? If you’ve been bumping into statistics maintenance issues, you’re probably already familiar with more of the hands-on intervention available (my personal favorite is Ola Hallengren’s solution).
Since we already know that the optimizer does not use statistics at the partition level, maybe we can parlay the potentially-higher sample rates into better plans with faster query execution times, or at least better resource utilization.
All tests were evaluated against a 1 percent sample rate non-incremental statistic on the large PostHistory table, using SQL Sentry Plan Explorer to capture relevant metrics. The query in question is a simple data pull across two partitions, with no aggregates.
[code lang=text] select PostCreationDate = p.CreationDate, PostOwner = pu.DisplayName, p.Title, pt.PostType, PostHistoryUser = phu.DisplayName, PostHistoryDate = ph.CreationDate, Comment from PostHistory ph join Posts p on ph.PostId = p.id and ph.SiteId = p.SiteId join Sites s on ph.SiteId = s.SiteId join PostTypes pt on p.PostTypeId = pt.PostTypeId join Users phu on phu.Id = ph.UserId and phu.SiteId = ph.SiteId join Users pu on pu.Id = p.OwnerUserId and pu.SiteId = p.SiteId where s.Address = ‘dba.stackexchange.com’ and ph.CreationDate >= ‘2014-06-30’ and ph.CreationDate < ‘2015-10-01’ order by p.CreationDate desc, ph.CreationDate desc option (recompile); [/code]
As a baseline, we see that the 1 percent, non-incremental index takes the following plan shape:

with these estimates/actuals (a common measure of stats validity):
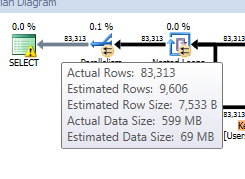
Finally, the information in the MemoryGrantInfo node of the plan XML shows the following:
[code lang=text]
Based on what we see here, we’ve got quite a discrepancy between estimated and actual row counts on both the final product and the actual object that we’re evaluating.
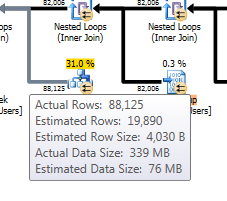
Our memory grant information shows us that if we’d chosen a serial plan, we’d have a required amount of 4 MB grant (internal structures required to begin the query). However, we can see that we got a parallel plan, which asked for a 323 MB grant. Of that amount, ~17 MB was “required” and we did spike to 24 MB of used memory in this query. So even though the we overestimated our grant request, it worked out for us because we got around a potential spill. A key part of generating these estimates is how the cardinality estimation process as that will influence the decisions made, not just for planning, but also for memory grant requests. “Additional memory” is a portion of the memory grant that is calculated based off of cardinality and row sze of the temporary set of rows in memory. An overestimate on the grant can lead to memory waste. An underestimate on the grant can lead to spills. In this case, we’ve overestimated and taken a grant that is nearly 300 MB more than we needed.
Does incremental stats help with this? At a 10 percent sample rate we lose the Key Lookup on the Users table, satisfying the request for the display name of the user who owns the original post with the previous seek on the CI/primary key. Interestingly, the second key lookup remains as it satisfies the request for the display name of a user who modified the original post in any way. Interestingly, though the plan shape changed, the estimates didn’t. Additionally, the overall CPU times and query times showed no discernable pattern of improvement as we moved from 1 percent to 10 percent. However, there was improvement in the memory grant and in reads. Both of these are explicable by the absence of the first key lookup on the Users table. Specifically, the difference in Required Memory can lead us to the removal of that operator as the explanation. SQL Server requires 512KB (the difference between the 1 percent and 1o percent SerialRequiredMemory) to set up an operator, and the requirement for a parallel query would be DOP * 512KB, or 2048KB which is the difference between the plans’ RequiredMemory attributes.
[code lang=text] Memory grant for incremental statistic sampled at 10 pct.
Curiously, at a 30 percent sample rate, the plan takes the original shape with the large memory grant and extra key lookup operator. The memory grant information remains the same for all sample rates, up to FULLSCAN. However, an analysis of PostHistory.CreationDate shows skewed data. A future test could be to analyze such a test on data that is more evenly distributed.
Conclusion
The results of this investigation should not be interpreted to mean that incremental statistics do not lead to performance gain on queries, because the investigation was so narrow. However, if my suspicion that statistics skew is the reason behind the consistently suboptimal plan generation, then at a certain row count the skew would be significant enough to cause poor cardinality estimate resolution regardless of sample rate. In this regard, incremental statistics on large partitioned tables, the ostensible target implementation, would provide no tangible performance benefit for plan generation.
Therefore, at this point, it seems the most conclusive thing that we can say about incremental statistics is that, based on my previous post, we can use incremental statistics to reclaim maintenance time and, perhaps, time on auto_update events.